Core contributor here, happy to try and answer any questions.
One of the big things we're working on at the moment is improving the release process. In addition to semantic versioning of the APIs we have to think through how it applies to the binary artifacts created. We want Go modules to be supported and be a part of the solution, but we are also mindful not to break things for existing users.
That is awesome one of the biggest pains I have with elasticsearch is how they so rapidly update major version number as like an excuse for breaking compatibility. IMO most important feature of a database is stability, this is something we get by maintaining compatibility with previous releases.
Thank you very much for Bleve! It was useful for me on a few projects. And, do not be afraid to break things in the future major version, modules are handling that nicely.
I was looking at it and wonder if I can plug it to remote database, or any abstract mechanism to store index in cloud space, I want to run it on cloud.
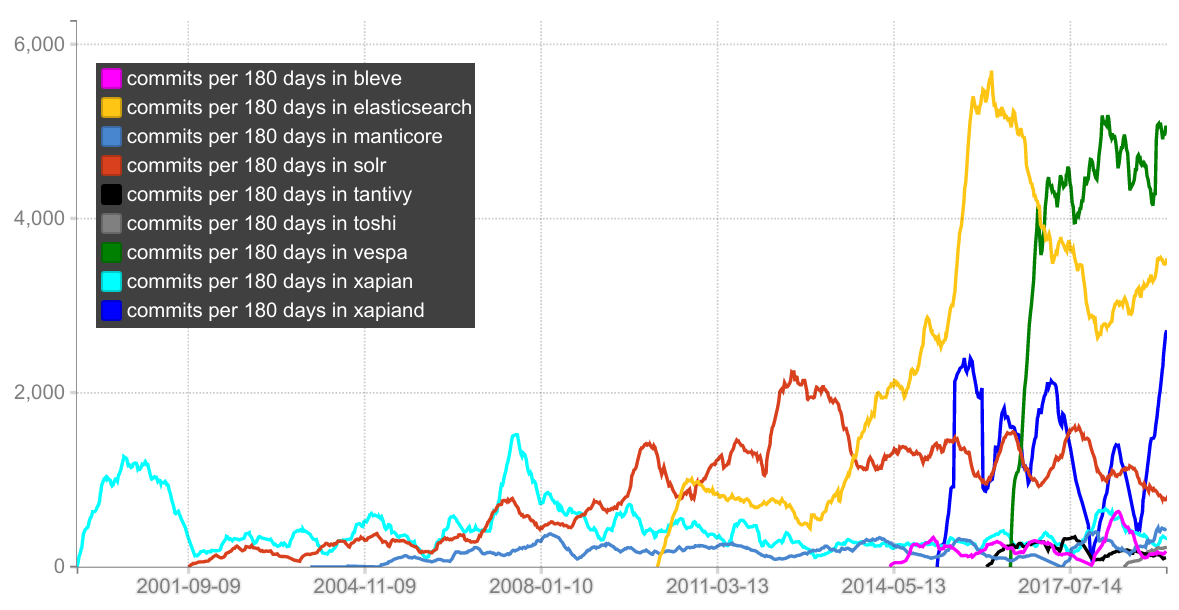
Great blog post! First one I've seen with good comparisons to the other options. I would recommend adding Xapiand too: https://github.com/Kronuz/Xapiand
I understand what it is but I'm not sure why it wasn't included. They forked specifically because nothing was happening in sphinx and they've been releasing new features.
Would you be willing to expand on this a bit? We run multiple elasticsearch clusters and there are pain points everywhere, I wonder where vespa improves?
For us, Vespa It is in a different league. Some quick things I remember:
- Native Tensor/ XGBoost support
- Automatic data partitioning and auto balancing( no need to set shards before hand)
- Jdisk (https://docs.vespa.ai/documentation/jdisc/) - This is the major feature for us. It enables us to create Distributed Applications that manipulate the search results directly on the nodes.
I'm not associated with the team, but I take every opportunity to promote it, as I think it is a very underrated project.
Really nice to see the Go ecosystem developing. The other day I was searching for a link/URL extraction library and the best one I could find was in Go: https://github.com/mvdan/xurls ("best" because it actually uses a list of TLDs, for example: https://github.com/mvdan/xurls/blob/master/tlds.go). Was an unusual experience not finding something as good for Java.
Any of the libvips bindings. Ffmpeg bindings. Hls and dash libraries. Any other wrappers around binaries in general. I found nice ports for syntax hi-lighting that I couldn’t find in java.
(author of Dgraph) We use specific libraries from Bleve to do, for e.g., full-text tokenization and such. But, we use our own indexing and storage mechanism, not Bleve's.
Indeed, bleve can be considered on the same level as lucene. It is used to power full-text search in Couchbase, which adds the distributed indexing and querying portion on top (similar to what elasticsearch does to lucene)
Bleve is awesome! In a page worth of code, I was able to make a really simple search for our app's documentation that takes almost no resources. Elastic would have been massive overkill.
I actually used this recently in a small personal project, it's pretty good. It's not like Elastic or Solr, more like Lucene - which may very well be good enough for your use case. The index structures are stored in BoltDB (which stores in a flat file.)
There are some issues, though. For example I think it's currently not possible to use the built-in query language to search Boolean values. So you might run into some minor issues even in smaller projects.
Bleve originated as part of a solution to a problem customers faced when using Couchbase. Almost all customers have at least some sort of search use case, but often times that use case isn't particularly complicated. Many of them were running an ES cluster, moving the data from Couchbase to ES with an adapter, and using that to solve their search use case.
However, many of those same users complained about having to operate another cluster, especially ones that weren't already using the JVM (since it was a skill set they didn't have).
So, the appeal was to offer a service that runs as a part of the Couchbase cluster. It wouldn't have to match every feature of ES, just shoot for 80/20 and customers would likely find it beneficial.
It was fortunate that Go was still growing in popularity within Couchbase at that time, and we were able to position Bleve as a true open-source component, on top of which some money-making value add could be layered.
Forgive my ignorance on the topic of full-text search but is this supposed to compete with Elastic or is this more of an alternative to Lucene? If the latter, then wouldn't you be limited to indexing text datasets small enough to stay in memory?
First, here are the top two requests that we do NOT plan to implement.
1. Make Bleve a distributed index, or make Bleve into something that is a more direct ES competitor.
We have no plans to do this because we think that is better built at a different layer. We have hooks we introduce in certain places where we need to plug-in code that would otherwise violate the boundaries. And that is an arrangement that has worked well so far. There are multiple projects built on top of bleve that allow you to index/search across nodes.
2. Make an adapter for the XYZ key/value store.
This request goes back to the original bleve index which is serialized into a key/value abstraction layer. When users run into size/speed issues with bleve, many assume that just plugging in a faster key/value store will help. (Hey we thought that too when we built it this way)
But, we've now replaced that index scheme with a new implementation called scorch. Scorch is considerably smaller and faster, and manages it's own index on disk, without using any key/value store.
As for things that we DO plan to implement:
1. Size of the index still comes up a lot. Couchbase is a very performnace sensitive user of Bleve, so I expect they'll lead the way on this front.
2. Better (pluggable) scoring. Today our search result scoring is broken for several types of queries, and the stuff that does score right is too tightly coupled to the searching logic.
3. Overhaul index mapping. Today bleve uses a mapping object to describe how source objects/documents are indexed. One of the best ways we can simplify the mapping is to make things more explicit. I think we tried to embrace the concept of reasonable defaults, but we ended up with inheritance hierarchies that are difficult to reason about.
There are lots of miscellaneous things like adding a data type that supports IPv6, or more advanced queries (lots of variations on span queries).
I'm looking at adding better search to our app soon, and I honestly don't really have knowledge of any systems out there. Answer to this basic question might help both me and others:
How would you deploy Bleve in a 12-factor app environment?
(Does Bleve directly support any persistence? Does it support distributed workloads? Could a "trained" model get passed to read-only nodes?)
Bleve is just a library that provides this functionality, you first have to build an application that uses Bleve, and deploy that.
Bleve does (optionally) support persistence, so reading/writing files is one place it does directly interact with the environment. The environment must support mmap.
There are several projects which support distributed index/search workloads with Bleve. The exact approaches vary, but they all use Bleve to perform node local operations, and coordinating this is done at a higher level by the application.
I suspect I don't understand the terminology you're using in the last question, as Bleve has no training, models or nodes.
{kind=link}
{kind=link}
One of the big things we're working on at the moment is improving the release process. In addition to semantic versioning of the APIs we have to think through how it applies to the binary artifacts created. We want Go modules to be supported and be a part of the solution, but we are also mindful not to break things for existing users.